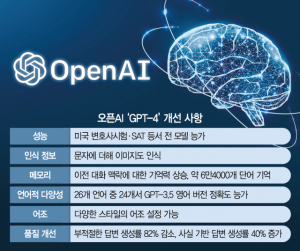
지난해 말 인공지능(AI) 챗봇 ‘챗GPT’를 선보여 전세계적인 신드롬을 불러일으켰던 오픈AI가 4개월도 안돼 업그레이드된 대규모언어모델(LLM)을 공개했다. 직전 버전에서 제기된 허점들을 보완하고 이미지 인식 기능을 추가했다. 기억력도 더 좋아져 미국 대학입학자격시험(SAT)를 상위 10% 수준으로 통과했다.
오픈AI는 14일(현지시간) 자사 LLM의 최신 버전인 ‘GPT-4’를 출시했다. 챗GPT에 적용된 ‘GPT-3.5’를 개량한 버전이다. 월 20 달러 유료 모델 ‘챗GPT 플러스’를 구독하면 사용할 수 있으며 애플리케이션 프로그램 인터페이스(API)도 활용할 수 있다.
직전 모델 대비 가장 눈에 띄는 점은 이미지 인식이 가능해졌다는 것이다. 이미지를 인식하는 타사 모델이 이미 나와 있지만 이 분야에서 선두를 달리는 오픈AI가 내놓은 첫 이미지 인식 모델이라는 점에서 큰 반향이 예상된다.
이미지 인식이 가능해진 만큼 생성 AI에 대한 쓰임도 광범위해질 것으로 보인다. 이미지에 대한 설명은 기본이고, 이미지를 제시한 뒤 이를 기반으로 시나 작문을 요청할 수 있고 이미지와 문자가 섞인 복잡한 정보에 대한 해석을 요구할 수도 있다. 문답 능력 자체도 크게 향상됐다. 오픈AI는 “일상적인 대화에서 큰 차이는 없을 수 있지만 작업이 복잡해지면 차이가 나타나기 시작한다”며 “새 모델은 더 안정적이고 창의적이며 훨씬 미묘한 지침을 처리할 수 있다”고 설명했다.
실제 GPT-4는 다수의 전문적인 시험에서 GPT-3.5를 압도하는 성적을 거뒀다. 미국 모의 변호사 시험에서 90번째, SAT 읽기와 수학 시험에서는 각각 93·89번째 백분위수를 기록하며 상위 10% 수준의 성적을 냈다. GPT-3.5의 경우 변호사 시험 등에서 하위 10% 정도의 성과를 기록했다. 다만 오픈AI는 성능과 직결되는 매개변수(파라미터) 수 등은 공개하지 않았다.
이전 모델에서 지속적으로 지적돼 온 추론 능력 부족과 할루시네이션(환각) 문제도 개선했다. 문장이나 단어를 통해 학습하기 때문에 취약했던 연산·추론력과 틀린 답도 그럴듯하게 내는 환각 문제는 LLM의 최대 약점으로 지적돼 왔다. 새 모델은 불법이나 비윤리적 대답을 낼 확률을 82% 줄이고 사실에 기반한 결과물을 제출할 가능성을 40% 높였다. 또 이전 버전에서 기억할 수 있는 단어가 약 8000단어 정도였는데 반해 새 버전에서는 최대 6만 4000단어로 늘어나 보고서 등을 요약하는 부분에서 편의성이 대폭 강화됐다.
비영어권 사용자에게는 아쉬웠던 외국어 능력도 향상됐다. GPT-4는 한국어를 포함해 26개 언어 중 24개 언어에서 직전 모델의 영어 버전을 능가하는 것으로 나타났다. API를 활용하면 기존 딱딱했던 어조도 다양하게 변주할 수 있다.
성능이 크게 개선됐음에도 오픈AI는 아직 갈 길이 멀다는 입장이다. 샘 알트만 오픈AI 최고경영자는 “GPT-4는 가장 유능한 모델”이라면서도 “여전히 결함이 있고 제한적이며 개선의 여지가 있다”고 말했다.
이경전 경희대 경영학·빅데이터응용학과 교수는 “튜링테스트를 통과했다거나 인간의 두뇌를 대체할 것이라는 등 루머에는 못미치지만 인류의 문화 유산을 이루는 또 하나의 축인 이미지를 학습했다는 점, 입력 토큰이 길이를 대폭 늘려 사용성을 크게 개선했다는 점이 눈에 띈다”며 “경쟁사에서 추격해오니 이미지 인식 기능을 탑재해 우위를 유지하려는 전략을 택한 것으로 보인다”고 말했다.









