“GPT 모델에 한계가 있다는 질문에 ‘아니다(No)’라고 말할 수 있다.”
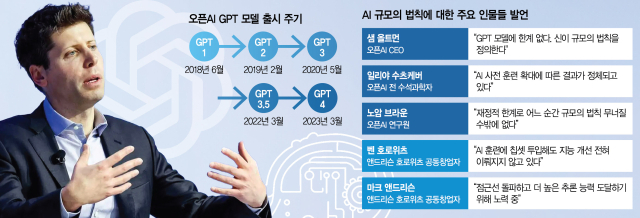
올 3월 서울경제신문과 만난 샘 올트먼 오픈AI 최고경영자(CEO)가 자신 있게 전한 말이다. 충분한 연산 자원이 투입된다면 현재 AI 모델의 기틀인 트랜스포머로 범용인공지능(AGI)을 구현하는 데 전혀 문제가 없다는 뜻으로 읽혔다. 당시 올트먼 CEO는 AI 인프라 개선을 위한 7조 달러(약 1경 원) 규모의 글로벌 펀딩을 추진하는 중이었다.
올트먼 CEO의 자신감은 연산량 투입과 비례해 AI 성능이 개선되는 ‘규모(scaling)의 법칙’에서 비롯됐다. 실제 2월 올트먼 CEO는 규모의 법칙이 적용될 것이라며 “규모의 법칙은 신이 정하고 기술진은 AI 모델 내 상수를 결정할 뿐”이라고 주장하기도 했다.
하지만 최근 들어서는 이러한 관측에 의문이 쏟아지고 있다. AI 혁명 최전선에 자리한 고위 인사들이 잇따라 ‘AI 발전은 느려지고 있다’고 지적하고 나선 것이다. 최근 오픈AI 투자사인 벤처캐피털(VC) 앤드리슨호로위츠(a16z)의 벤 호로위츠 공동창업자는 “AI를 훈련하는 데 사용되는 그래픽처리장치(GPU) 수를 같은 속도로 늘리고 있으나 지능 개선이 전혀 이뤄지지 않고 있다”고 밝혀 충격을 줬다.
오픈AI 공동창업자이자 수석과학자로서 ‘올트먼 축출 사건’을 일으켰던 일리야 수츠케버도 최근 로이터와의 인터뷰에서 “AI 모델 사전 훈련 확대에 따른 결과가 정체되고 있다”는 우려를 드러냈다. 디인포메이션은 오픈AI가 GPT-5 개발 과정에서 겪고 있는 어려움이 구글 제미나이 2.0 개발 과정에서 똑같이 나타나고 있다고 보도했다. 막대한 데이터를 투입해 훈련시켰지만 기대만큼의 성능 개선이 이뤄지지 않아 신형 AI 모델의 출시가 지연되고 있다는 것이다.
2022년 11월 챗GPT 등장 이후 AI 혁명의 도래를 의심치 않던 테크계로서는 이 같은 속도 지연 현상이 ‘AI 버블’에 대한 우려를 키우는 요소로 작용하고 있다. 불과 1년 전인 2023년 말은 생성형 인공지능(AI) 성능 경쟁이 절정에 달하던 때였다. 당시 화두는 ‘초거대 AI 경쟁’이었다. 포문은 지난해 11월 첫 개발자회의를 연 오픈AI가 열었다. 오픈AI는 GPT-4를 한층 개선한 ‘GPT-4 터보’를 공개했다. 성능이 개선된 한편 더 긴 텍스트를 인식할 수 있게 됐고 이미지·음성 인식까지 가능한 멀티모달 AI가 나오며 시장에 충격을 안겼다. 이어 12월에는 생성형 AI 원조인 구글이 제미나이 울트라·프로 1.0을 선보이며 AI 경쟁에 본격적으로 뛰어들었다. 해를 넘겨 올해 2월에는 구글이 제미나이 1.5를 선보였고 오픈AI 라이벌로 꼽히는 앤스로픽도 클로드-3을 선보이며 생성형 AI 대전이 펼쳐졌다.
당시만 해도 ‘거대화’를 통한 성능 개선에 집중하던 AI 업계는 6개월 전부터 분위기가 급변했다. 5월에 선보인 오픈AI GPT-4o는 빠른 응답 속도와 모델 경량화, 그리고 자연스러운 대화 기능에 방점을 찍었다. 구글도 연례개발자회의 구글 I/O 2024에서 경량화한 제미나이 1.5 플래시와 대화·시각인식을 강화한 프로젝트 아스트라를 공개했다. 앤스로픽 역시 6월에 기존 대비 2배 빨라진 클로드-3.5를 선보였다. 주요 AI개발사들이 경량화 및 챗봇 기능 도입에 주력하기 시작한 것이다.
올 하반기 들어서는 ‘추론’과 ‘서비스 세분화’로 분화하는 양상이 더욱 뚜렷해졌다. 추론에 투입하는 시간을 늘려 ‘외계어’로 쓴 한글 문장을 인식하는 모습을 시연해 충격을 준 오픈AI-o1이 대표 사례다. 앤스로픽 또한 10월에 PC 화면을 인식해 자동 작업이 가능한 AI 에이전트를 공개했다. 구글은 워크스페이스·지도 등 자사 서비스에 제미나이를 이식하며 사용성 개선에 집중하고 있다.
더 많은 연산 자원 투입과 모델 대형화를 통한 성능 개선에 집중하던 AI 개발사들이 우회로를 찾고 있다는 분석이 잇따르는 배경이다. AI 인프라 투자 비용이 폭증하는 상황에서 시간이 갈수록 효율이 떨어지는 규모의 법칙에 매달리기보다는 고객 친화적인 서비스 개선을 통해 출구를 모색하고 있다는 해석이 나온다. 실제 노암 브라운 오픈AI 연구원은 10월 TED AI 콘퍼런스에서 “수천억, 수조 달러가 드는 모델을 훈련하는 건 재정적으로 불가능해 어느 순간 규모의 법칙이 무너질 수밖에 없다”고 인정해 업계에 충격을 안겼다.
더 나아가 학습할 데이터에 한계가 있다는 점도 걸림돌로 작용한다. 콘텐츠 저작권 소송이 이어지고 있는 데다 인터넷상에 공개된 데이터 대다수를 이미 학습해 ‘데이터 고갈’이 벌어지고 있다. 사정이 이렇게 되자 오픈AI와 구글은 최근 AI 훈련에 AI로 생성한 데이터를 활용하고 있다. 디인포메이션은 “구글이 제미나이 2.0 훈련 과정에서 생성 데이터를 사용했으나 이렇다 할 효과를 보지 못했다”고 지적했다.









