 국립국어원 올해 말뭉치 25종 1억2000만 어절 규모 공급 계획
국립국어원 올해 말뭉치 25종 1억2000만 어절 규모 공급 계획문화체육관광부는 챗GPT로 대표되는 생성형 AI 기술이 가져올 거대한 변화에 필요한 문화적·제도적·산업적 기반을 마련하기 위해 3개의 워킹그룹을 발족한다고 22일 밝혔다. 이를 통해 △저작권 제도의 개선 △ ‘한국어 잘하는 AI’를 위한 한국어 말뭉치 학습 △ 콘텐츠 창작과 산업에서의 AI 활용 등 3가지 분야 논의를 진행한다.
우선 문체부는 AI 기술발전에 따른 저작권 제도개선 방향을 논의하기 위해 24일 오후 4시 한국저작권위원회 서울사무소에서 AI-저작권법 제도개선 워킹그룹을 발족한다. 저작권 제도 개선 워킹그룹에서는 △ AI 학습데이터에 사용되는 저작물의 원활한 이용 방안 △ AI 산출물의 법적 지위 문제 및 저작권 제도에서의 인정 여부 △ AI 기술 활용 시 발생하는 저작권 침해와 이에 대한 책임 규정 방안 등을 논의한다.
문체부는 앞서 2021년 AI 등 신기술 환경에서 저작권 제도의 개선 방향을 논의하는 협의체를 운영한 바 있다. 다만 최근 챗GPT 논의가 폭발적으로 이루어짐에 따라 관련한 저작권 문제가 다시 부상하고 있어 학계와 법조계, AI 산업계와 창작자 등 현장 전문가 및 이해관계자의 논의가 더 필요하다는 이유에서다.
워킹그룹에서는 저작권 제도와 AI 기술이 융합할 수 있도록 변화된 시대에 맞는 제도의 방향에 대해 폭넓게 논의한다. 특히 현행 저작권법 내에서 활용될 수 있는 (가칭)‘저작권 관점에서의 AI 산출물 활용 가이드(안)’을 마련하는 등 신산업으로서의 AI의 발전을 지원하면서도 인간 창작자들의 권리를 공정하게 보장할 수 있도록 합의점을 모색한다. 워킹그룹은 2월부터 9월까지 8개월간 운영된다.
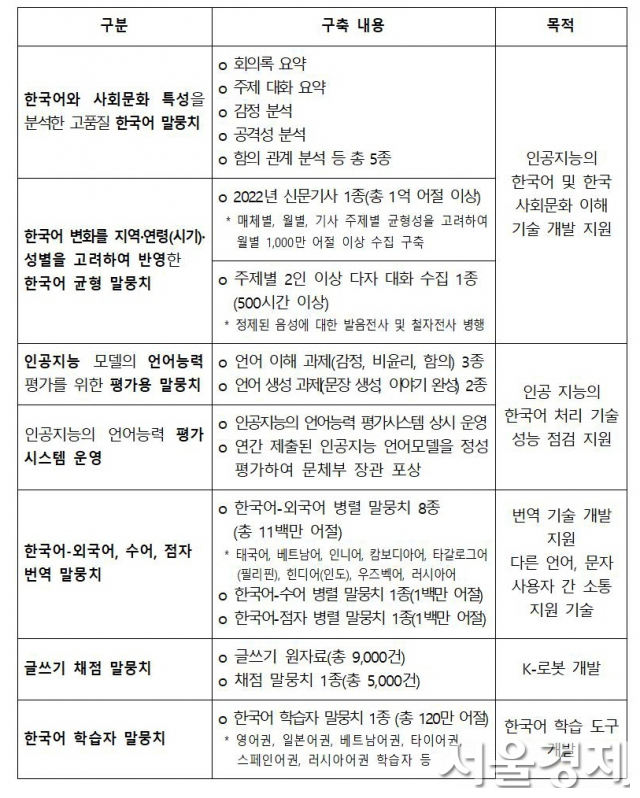
그동안 챗GPT를 사용해 본 많은 사람들은 한국어 대응이 아쉽다는 반응을 보인다. 영어권에서 개발돼 한국어 학습이 영어만큼 충분하지 않아서다. AI의 한국어 학습을 위해서는 한국어 특성을 반영한 고품질의 한국어 말뭉치가 필요한 이유다.
문체부와 국립국어원은 ‘한국어를 잘하는 K-챗GPT’ 개발을 지원하기 위해 고품질 한국어 말뭉치 구축을 확대하고, 워킹그룹 운영을 통해 현장이 필요로 하는 말뭉치를 제공할 계획이다. 앞서 2018년부터 구축된 대규모 한국어 말뭉치 37종(약 22억 어절)은, 국립국어원 말뭉치 공개 사이트(모두의 말뭉치)를 통해 오픈소스로 제공되어 한국어 인공지능 개발에 활용돼 왔다.
고품질의 말뭉치는 사람이 직접 말뭉치에 한국어 분석 정보를 입력하고 검수하는 과정을 거친다. 이런 과정에 비용이 많이 들기 때문에 한국어 말뭉치 제공은 스타트업의 언어자료 구축 비용을 절감하고, 이미 개발된 인공지능 기술을 고도화하는 데 기여해왔다.
이에 더해 문체부는 인공지능 개발 현장 수요를 즉각적으로 파악할 수 있는 워킹그룹을 23일 준비 회의를 거쳐 3월부터 8월까지 운영한다. 워킹그룹은 인공지능과 말뭉치 구축 전문가, 학계 전문가, 문체부와 국립국어원 연구원으로 구성되며, 인공지능 기술 개발에 필요한 말뭉치 수요를 파악하고, 2027년까지 한국어 특성을 반영한 고품질 말뭉치 10억 어절 구축 계획을 세울 예정이다.
올해 문체부는 한국형 챗GPT가 빠르게 개발될 수 있도록 25종, 약 1억 2000만 어절의 고품질 한국어 말뭉치를 구축해 배포한다. 또한 인공지능 언어모델이 한국어를 잘 이해하고 생성하는지, 한국의 사회문화 지식을 갖추고 있는지를 검증하는 평가시스템을 시범 운영할 계획이다.
이와 함께 문체부는 콘텐츠 산업 분야에서의 AI 활용에 능동적으로 대응하기 위해 우리나라 AI의 선구자인 김진형 한국과학기술원 명예교수를 비롯해 AI 관련 학계와 업계 관계자 9명으로 구성된 ‘콘텐츠 분야 AI TF’를 구성했다.
9명은 김진형 한국과학기술원 전산학부 명예교수, 이만재 아주대 미디어학부 전 교수, 허문행 안양대 명예교수, 김윤명 경희대 교수, 우창헌 인천재능대 AI컴퓨터정보과 교수, 김태희 영산대 게임VR학부 교수, 서유미 딥브레인 AI 리더, 박지은 펄스나인 대표, 조영환 Two Bloc AI 대표 등이다.
지난 2월 15일 열린 첫 회의에서는 AI의 활용 범위가 문화, 콘텐츠로 빠르게 확대되는 추세에 발맞춰 콘텐츠 산업에 AI가 성공적으로 내재화할 수 있도록 상반기까지 정기적으로 회의를 개최해 △ AI를 활용한 신뢰 가능한 콘텐츠 제작환경 조성 △ 콘텐츠 기획과 제작자들의 AI 활용 마인드 확산 △ 민간주도 시장성장을 위한 AI 콘텐츠 스타트업 육성과 대기업 협업 등을 위한 방안을 본격적으로 논의하기로 했다.
특히 최근 이슈가 되고 있는 챗GPT 등 생성형 AI가 콘텐츠 산업 분야에 미칠 영향과 다양한 이슈를 파악하고, 콘텐츠 산업에 적용사례를 조사 분석해 이에 따른 정책적 지원 방안을 중점적으로 제안하기로 했다.
이 밖에 생성형 AI를 잘 이해하고, AI 콘텐츠 시장을 이끌 수 있는 인재 육성 방안도 모색한다. 문체부는 TF를 통해 청취한 의견과 제언을 종합해 AI를 활용한 콘텐츠산업 분야 지원 대책을 올해 5월까지 마련할 계획이다.









