 21일(현지 시간) 미국 루이지애나주 뉴올리언스 모리얼 컨벤션 센터에서 열린 ‘국제 컴퓨터 비전 및 패턴 인식 학술대회(CVPR) 2022’에서 참가자들이 LG 부스를 둘러보고 있다. 이날 LG그룹에서는 LG AI연구원, LG전자를 비롯한 6개 계열사가 총출동했다. 사진 제공=LG
21일(현지 시간) 미국 루이지애나주 뉴올리언스 모리얼 컨벤션 센터에서 열린 ‘국제 컴퓨터 비전 및 패턴 인식 학술대회(CVPR) 2022’에서 참가자들이 LG 부스를 둘러보고 있다. 이날 LG그룹에서는 LG AI연구원, LG전자를 비롯한 6개 계열사가 총출동했다. 사진 제공=LG21일(현지 시간) ‘국제 컴퓨터 비전 및 패턴 인식 학술대회(CVPR) 2022’가 열린 미국 루이지애나주 뉴올리언스 모리얼 컨벤션 센터는 인공지능(AI) 기술의 현주소를 확인하려는 세계 각국의 연구진들로 인산인해를 이뤘다. 컴퓨터 비전은 AI 중 시각영역에 초점을 맞춘 분야로 AI 중에서도 최신 연구 영역으로 꼽힌다.
이날 학회를 찾은 전문가들은 현장에 마련된 LG의 초거대 AI 시스템인 엑사원의 시연에 주목했다. 텍스트를 입력하면 이미지가 도출되고 반대로 이미지를 입력하면 이를 문장으로 바꿔주는 양방향 변환 기술은 LG AI연구원만이 구현하고 있는 기술이어서다.
엑사원에 ‘동화 삽화 같은 산 풍경’이라는 문장을 입력해봤다. 멀리 구름이 걸려 있는 산 이미지를 비롯해 파란 달이 비치는 하얀 설산 이미지 등 AI가 직접 생성한 이미지 수백 장이 나타났다. 색채·구도·스타일·배경 등이 다양하게 창조됐다. 김승환 LG AI연구원 비전랩장은 “한 문장으로 원하는 이미지를 설명하면 AI가 256장가량을 생성하는 데 7~8분이 걸린다”고 설명했다.
이번에는 엑사원에 스키를 타는 이미지를 넣어봤다. 엑사원은 ‘노란색 스키복을 입은 청년이 스키를 타고 하얀 설산을 내려오고 있다’는 문장을 내놓았다. 최대 64개의 단어로 해당 이미지를 구체적으로 표현하는 게 엑사원의 장점이다. 표현하는 단어가 많아질수록 데이터는 정교해지기 때문이다.
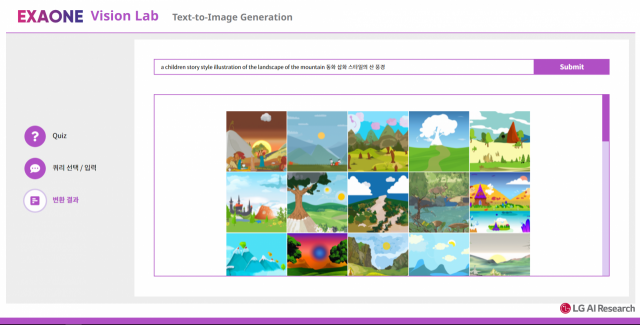 LG의 초거대 인공지능(AI)인 엑사원에 ‘동화 삽화 스타일의 산 풍경’이라는 콘셉트를 입력하자 나타난 수백 가지의 이미지. 사진 제공=LG
LG의 초거대 인공지능(AI)인 엑사원에 ‘동화 삽화 스타일의 산 풍경’이라는 콘셉트를 입력하자 나타난 수백 가지의 이미지. 사진 제공=LG이미지와 텍스트의 양방향 전환은 현재까지 LG의 엑사원만이 구현할 수 있는 기술이다. 구글의 AI인 ‘이매진’이나 알파벳의 자회사 딥마인드의 ‘플라밍고’는 텍스트를 이미지로 변환하는 한 방향의 모델만 채택한다. 가장 작은 단위로 나눠도 여전히 의미를 갖고 있는 텍스트와 달리 이미지는 타일 형식으로 쪼갰을 때 의미가 없다. 속성이 그만큼 달라 양방향 전환이 어렵다는 의미다. LG AI연구원은 이 과제를 풀어내면서 이날 학회의 주목을 이끌어냈다. 글로벌 이미지 아카이브 플랫폼도 협력 제안을 해왔다. 김 비전랩장은 “컴퓨터 비전의 궁극적인 지향점은 사람의 눈처럼 똑똑한 AI를 만드는 것”이라며 “이미지를 텍스트로, 다시 이미지로 변환하는 과정에서 일어나는 데이터 정교화 작업은 인간이 스스로 학습하는 방식에 가깝다”고 설명했다.
엑사원은 LG의 AI휴먼인 ‘틸다’의 두뇌 역할을 한다. 김 랩장은 “엑사원이 발전할수록 틸다는 사람처럼 오감을 인지하게 될 것”이라고 강조했다.
 21일(현지 시간) 미국 루이지애나주 뉴올리언스 모리얼 컨벤션 센터에서 김승환 LG AI연구원 비전랩장이 인터뷰 후 LG의 초거대 AI 엑사원을 활용해 변환된 이미지를 소개하고 있다. 뉴올리언스=정혜진 특파원
21일(현지 시간) 미국 루이지애나주 뉴올리언스 모리얼 컨벤션 센터에서 김승환 LG AI연구원 비전랩장이 인터뷰 후 LG의 초거대 AI 엑사원을 활용해 변환된 이미지를 소개하고 있다. 뉴올리언스=정혜진 특파원 LG의 AI휴먼 ‘틸다’. 사진 제공=LG
LG의 AI휴먼 ‘틸다’. 사진 제공=LG한편 올해 CVPR을 휩쓴 키워드는 두 개 이상의 감각을 변환하는 AI 모델인 ‘멀티 모달’이었다. 텍스트와 이미지를 변환하는 기술은 물론 여기에 음성 변환까지 더해진 연구들도 나왔다. 국내 AI반도체 스타트업 퓨리오사도 AI반도체 ‘워보이’를 통해 초당 영상 10개(300프레임)에 달하는 데이터를 처리하고 영상 속 움직임을 인식할 수 있는 기술을 시연했다. AI 권위자인 한보형 서울대 교수는 “모든 종류의 데이터를 하나의 모델로 내놓아 범용적으로 풀 수 있는 모델에 대한 연구가 강조되는 경향”이라고 짚었다.









